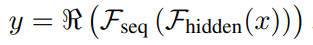최근 pretrained model을 이용하여 높은 퍼포먼스를 보여주는 연구가 많은데
이 논문은 pretraining의 높은 비용(낮은 효율성)을 지적한다.
가령 Vision Transformer가 ImageNet 22K에서 pretrain한 뒤,
ImageNet 1K로 downstream하는 방식의 finetuning을 하는데,
이는 pretraining 과정에 이미지 22K장의 방대한 양을 학습해야하기 때문에 상당한 비용이 요구된다.
논문은 22K장의 이미지를 이용하지 않고도 22K장을 이용한 만큼 혹은 그 이상의 퍼포먼스를 보여줄 수 있는 방법을 제시한다.
아이디어는 간단하다. ImageNet 1K에 supervised set up으로 pretrain된 teacher model을 이용해
unlabeled set에서 각 category별로 score가 높은 top k개를 골라내어
추가적인 학습에 사용하고, 나머지 데이터는 사용하지 않는다.
공정한 비교를 위해 teacher 모델이 데이터를 선별하는 과정 전에
SIFT[2]라는 기법을 이용해 validation set과 비슷한 이미지를 미리 제외해준다.
예를 들면, ImageNet 22K에서 SIFT를 이용해 ImageNet 1K의 validation set과 비슷한 이미지를 제외하고,
ImageNet 1K에서 pretrain된 ResNet50을 teacher model로 사용하여,
앞서 제외하고 남은 이미지 중 각 클래스별 score가 높은 4000개를 선별하여 4M개만 사용한다.
결과
Result1
전체 데이터를 활용하여 학습하는 것보다
일부 데이터로 한번 학습을 끝내고,
남은 데이터를 선별해 추가적인 학습을 하는 것이
더 정확도가 높은 것을 알 수 있다.
Result2
다른 아키텍쳐를 사용했을 때도 같은 결과를 얻는다.
개인적인 생각
스크래치부터 학습할 것 없이,
현재 널려있는 pretrained 모델부터 출발한다는 아이디어는 훌륭하다.
그러나 한번 학습을 끝낸 모델을 기준으로 데이터를 선별하는 것이
치팅인지 아닌지 여부가 관건이다.
공정한 과정을 거쳤다고는 하나
결국 테스트셋과 닮은 데이터를 뽑아내는 것인데
어디까지가 공정하다고 할지 애매하다.
Reference
Cheng Cui, Ruoyu Guo, Yuning Du, Dongliang He, Fu Li, Zewu Wu, Qiwen Liu, Shilei Wen, Jizhou Huang, Xiaoguang Hu, Dianhai Yu, Errui Ding, Yanjun Ma
Beyond Self-Supervision: A Simple Yet Effective Network Distillation https://arxiv.org/abs/2103.05959
David G Lowe. Object recognition from local scale-invariant features. In Proceedings of the seventh IEEE international conference on computer vision, volume 2, pages 1150–1157. Ieee, 1999.
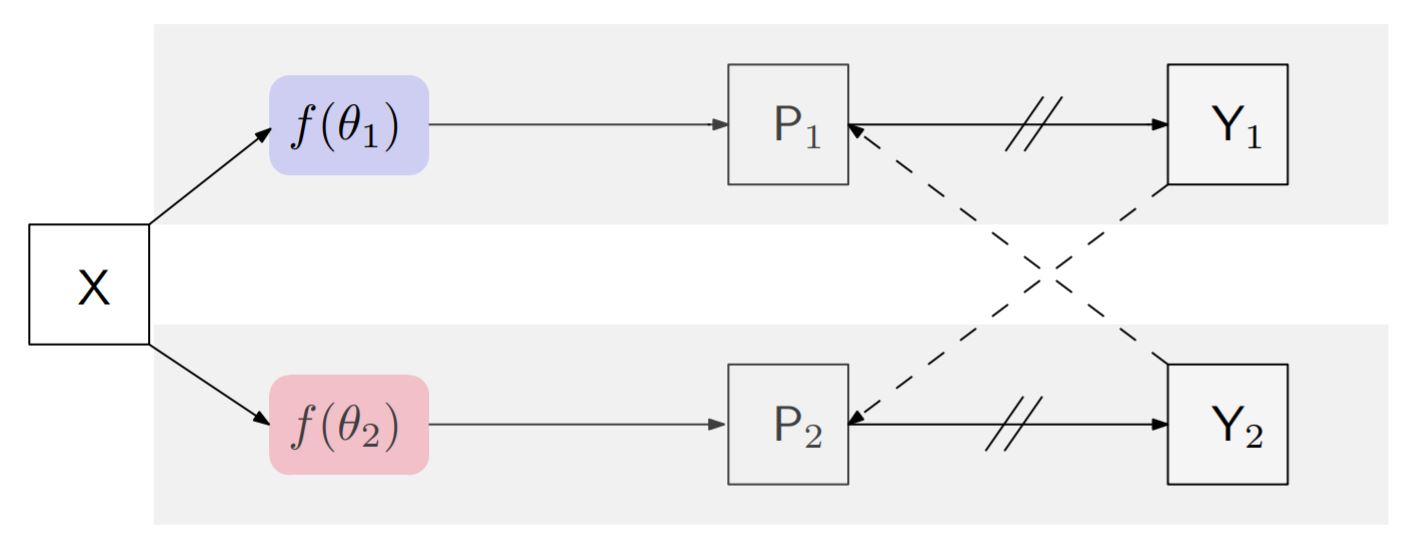
레이블이 있는 데이터는 supervised setup으로 학습하고 레이블이 없는 데이터는 한 데이터를 두 개의 모델에 통과시키고
각 예측값을 교차하여 stop gradient를 해주고 서로 다른 모델의 수도 레이블로 간주하여 학습한다.
loss는 다음과 같다.
$\mathcal{L} = \mathcal{L}_{s} + \lambda \mathcal{L}_{cps}$
supervised loss $\mathcal{L}_s$와 cross pseudo supervised loss $\mathcal{L}_{cps}$의 합으로 구성된다.
Cross pseudo supervision는 unlabeled 뿐만아니라 labeled 데이터에 대해서도 수행하기 때문에 loss는
$\mathcal{L}_{cps} = \mathcal{L}_{cps}^{l} + \mathcal{L}_{cps}^{u}$이다.
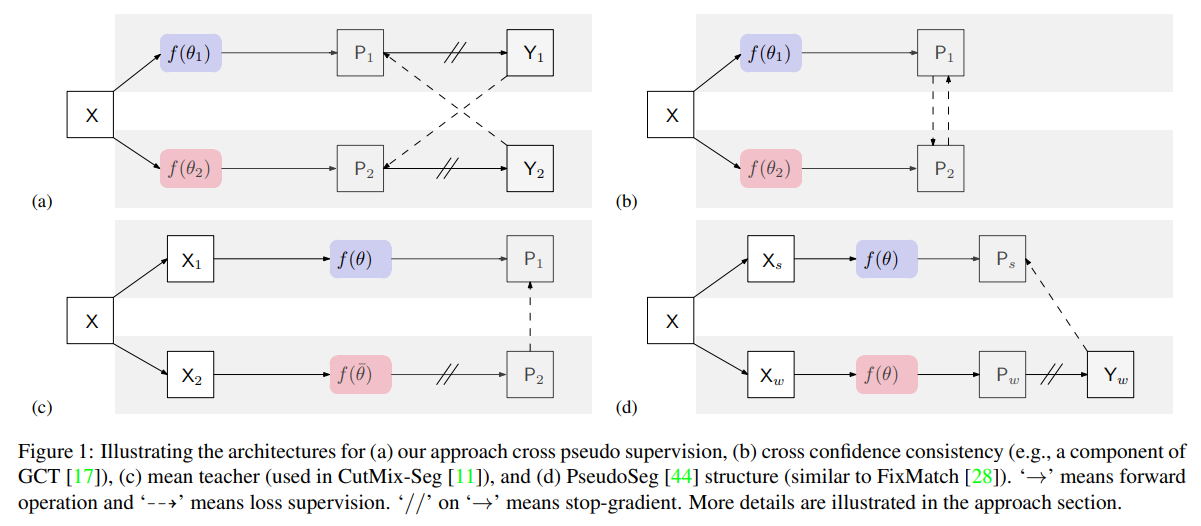
Semi supervised learning을 위해
두 개의 모델을 이용하거나 Stop gradient(//)을 이용한 비슷한 연구와 비교하였다.
Comparison with related work
이 중 (c) student와 teacher를 활용하여 teacher를 student의 average로 업데이트하는 방식보다 더 잘 된다는 것이 놀라웠다.
왜냐하면 보통 weight averaging을 통해 학습하는 것이 좀 더 general한 결과를 만들기 때문에
퍼포먼스 향상이 꽤 보장된다.(궁금하다면 Stochastic Weight Averaging에 대해 검색해보길 추천한다.)
그런데 이런 average 방식 없이 훨씬 간단하게 두 모델의 아웃풋을 cross하여 label로 SGD 하는 것이 더 나은 결과를 만들었다는 점이 인상적이다.
하이퍼파라미터도 추가되는 것 없이 다른 semi-supervised setup에서도 사용되는 loss 사이의 가중치($\lambda$)만 있기 때문에 여러 도메인에 안정적으로 적용하기 쉽다.
결과
PASCAL VOC 2012 val과 Cityscapes val에서 모두 SOTA를 달성하였다.
CutMix를 결합하여 정확도를 조금 더 끌어올렸다.
Reference
Xiaokang Chen, Yuhui Yuan, Gang Zeng, Jingdong Wang
Semi-Supervised Semantic Segmentation with Cross Pseudo Supervision https://arxiv.org/abs/2106.01226
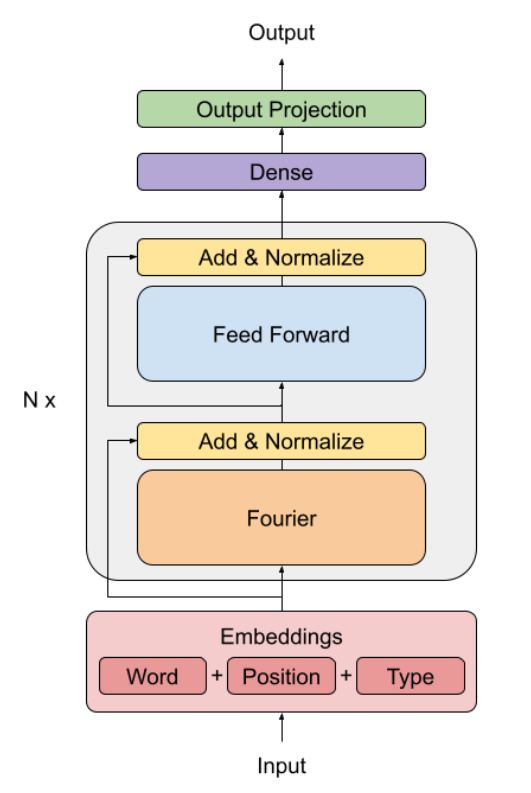
2D Fourier transform을 self-attention 대신 적용하며,
두 개의 1D Fourier Transform $\mathcal{F}$을 hidden dimension과
sequence dimension에 두 번 연속으로 적용하는 방식을 채택한다.
두 번 fourier transform을 수행하고, 실수부(real part; $\Re$)만 output으로 사용한다.
두 개의 fourier transform에서 모두 real part를 사용하는 것보다
두 번째 output에만 사용하는 것이 더 나은 결과를 보여준다고 한다.
두 번 모두 real part를 사용할 때 기대되는 speed up은 관찰되지 않았다.
배경
Discrete Fourier Transform(DFT)
푸리에 변환은 주어진 함수를 몇 개의 주파수로 분해하는데,
이산 푸리에 변환(DFT)는 이산적인 입력 신호로 분해하며, 공식은 다음과 같다.
$X_k = \sum_{n=0}^{N-1} x_n e^{-\frac{2 \pi i}{N} n k}, \; 0 \leq k \leq N - 1 $
$N$개의 이산적인 복소수 $x_i$들을 복소수 $X_i$들로 변환된다.
푸리에 변환이 self-attention을 대체한다고 생각했을 때,
$x_i$가 input token이며, 새로운 복소수 $X_i$가 layer의 output이다.
DFT 방법 첫 번째
DFT를 계산하는 첫 번째 방법은 Fast Fourier Transform(FFT)으로,
대표적인 FFT는 Cooley-Tukey algorithm이 있다.
이 알고리즘은 Sequence length $N$을 $N = N_1 N_2$로 표현하여
계산량을 $O(N \log N)$으로 줄인다.
DFT 방법 두 번째
DFT를 계산하는 다른 방법은 단순히 DFT matrix를 input sequence에 곱하는 것이다.
DFT matrix는 Vandermonde matrix로 normalize되어 다음과 같이 구성된다.
$W_{nk} = ( \frac{e^{-\frac{2 \pi i}{N} n k}}{\sqrt{N}})_{nk}$
연산량은 더 많지만 TPU의 효과적인 matrix multiplication으로 인해 상대적으로 짧은 길이의 sequence에서는 속도가 더 빠르다고 한다.
결과
트랜스포머를 최적화하기 위한 다른 기법(Adafactor, inverse square root learning schedule, and pre-layer normalization)을 사용하지 않고,
Vanilla Transformer와 비교하기 위해 vanilla FNet만을 실험하였다.
비교를 위해 BERT-Base transformer, Linear encoder, Random encoder, Feed Forward only(FF-only) 모델을 사용했다.
Linear encoder는 2개의 learnable한 linear layer로 self-attention을 대체하며 각각 hidden dimension과 sequence dimension에 적용된다.
Random encoder는 2개의 random한 값을 가진 matrix로 self-attention을 대체하며 각각 hidden dimension과 sequence dimension에 적용된다.
FF-only는 self-attention layer를 아예 제외하고 feed forward layer로만 학습한다.
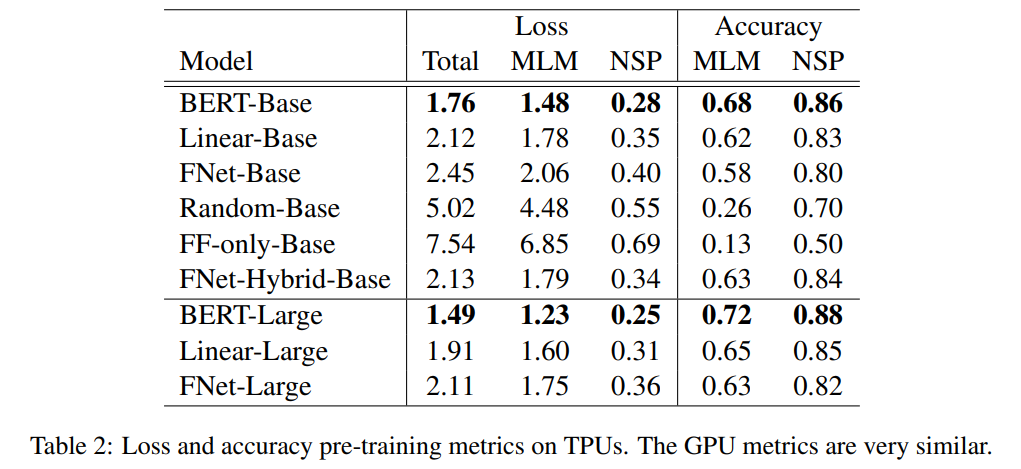
Table 2를 보면 정확도는 BERT가 Base와 Large 모델 모두 가장 높다.
FF-only Base 모델의 NSP의 정확도가 0.5인데 binary task이기 때문에 학습이 되지 않았다고 볼 수 있다.
이는 token mixing의 필요성을 나타내는 결과다.
Token mixing을 하는 Linear-Base, Random-Base를 FNet-Base와 비교해보자.
먼저 Random-Base도 token mixing이 되긴 된다. 하지만 정확도가 월등히 낮다.
그런데 Linear는 Base와 Large model에서 둘 다 FNet보다 정확도가 높다.
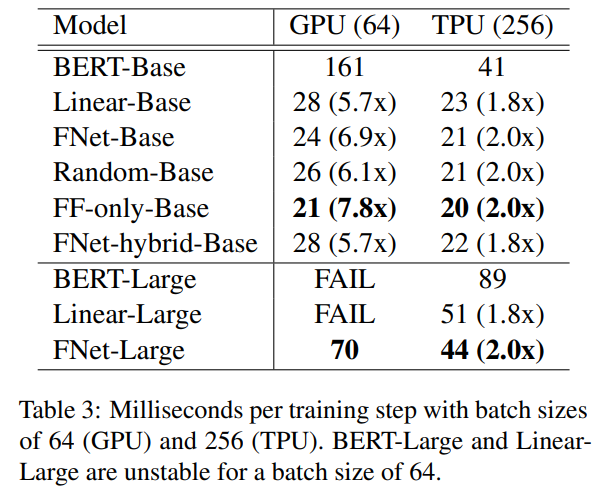
Table3을 보면 FNet이 Linear 모델보다 나은 점은 속도와 학습의 안정성에 있다는 것을 알 수 있다.
Token mixing을 하는 모델 중 FNet이 GPU와 TPU에서 둘 다 가장 빠르고,
Batch size를 64로 줄였을 때도, 학습이 실패한 BERT나 Linear와는 달리 안정적으로 되는 것을 볼 수 있다. Fourier transform을 사용했기 때문에 학습할 파라미터가 없어 속도와 안정성을 획득한다고 해석할 수 있다.
또한 task independent하고 token independent한 방식임에도 적당한 token-mixing을 통해 정확도를 어느정도 끌어올릴 수 있다는 이점이 있다.
이 논문은 Long Range Arena(LRA)라는 이름의 Benchmark Dataset에 대해 설명하는 논문으로, 트랜스포머 모델이 긴 시퀀스에 대해 얼마나 효과적인지 평가하기 위한 데이터셋이며, 6가지 서브 태스크로 구성되어있다.
트랜스포머 모델의 self-attention은 행렬곱 연산으로 인해 token의 길이가 길어지면 complexity가 quadratic하게 증가하고,
거리가 먼 token간의 연관성을 학습하는데 어려움을 겪는다.
긴 시퀀스 문제를 트랜스포머로 해결하고자 할 때, 어떤 요소를 통해 평가할지 고민하고, 그에 맞는 여러 서브 데이터셋을 제시하였다.
각 태스크의 시퀀스의 길이는 1K에서 16K까지 다양하며, text, natural, synthetic images, mathematical expressions 등 여러 modality의 데이터로 구성되었다.
각 데이터셋에 대하여 지금까지 나온 유명한 트랜스포머 아키텍쳐 몇 개를 선정하여 baseline을 제시하였다.
Desiderata: 이 데이터셋이 추구하는 것
Generality: 여러 태스크에 적용이 가능해야 한다. 가령 모든 트랜스포머 모델이 autoregressive decoding이 가능한 것은 아니기 때문에 encoding으로만 할 수 있는 태스크로 구성한다.
Simplicity: 태스크가 간단해야 한다. 특정한 augmentation이 필요하거나, 외부 데이터셋에서 pretraining이 필요한 경우는 제외한다.
Challenging: 충분히 어려워서 연구할만한 가치를 지녀야한다.
Long inputs: Input sequence length가 충분히 길어야한다.
Probing diverse aspects: 각 서브 태스크는 다른 요소를 평가할 수 있어야한다. 예를 들어, relation, hierarchical/spatial structures, generalization capability 등의 요소가 내재되어야한다.
Non-resource intensive and accessible: 컴퓨팅 리소스에 구애받지 않도록 lightweight한 규모로 구성한다.
태스크
LONG LISTOPS
긴 맥락에서 hierarchical structure을 모델링할 수 있는지 평가하는 태스크다.
데이터셋은 Max, Mean, Median, 그리고 Sum_mod 연산이 괄호와 함께 포함되어있으며, 0에서 9까지 10개의 클래스로 분류하는 문제다.
구체적인 Input과 Output의 예시는 다음과 같다. Input: [ MAX 4 3 [ MIN 2 3 ] 1 0 [ MEDIAN 1 5 8 9, 2 ] ] Output: 5
문제는 간단하다. Input의 연산을 풀어서 답을 찾으면 되고,
답도 0에서 9까지만 있어 분류 문제다.
사람이 위 문제를 풀기 위해선 다음의 사고 과정을 거친다.
먼저 우선적으로 풀어야하는 괄호를 찾아 Min값 2(2와3중에 2)과 Median값 5(1,2,5,8,9 중에 5, 쉼표(,)는 노이즈다.)를 구하고
해당 괄호 부분을 2와 5로 대체하여 준다([MAX 4 3 2 1 0 5]).
그 다음 Max값 5(4,3,2,1,0,5 중에 5)를 얻는다.
이러한 기다란 수학 문제로 구성된 논리적인 구조를 트랜스포머가 풀 수 있는지 확인할 수 있는 태스크다.
단, Input은 텍스트 데이터로 입력받으며 길이가 최대 2,000까지 된다.
BYTE-LEVEL TEXT CLASSIFICATION
Byte/character-level에서의 language modeling(char LM)이다.
단어 단위로 토큰을 만드는 것이 아니라
알파벳 하나 단위로 토큰을 만드는 것이다.
예를 들면, 영어 사용자는 appl의 다음 알파벳은 e가 나올 것 같은 맥락 정보를 생각할 수 있다.
이렇게 글을 알파벳 단위로 작게 나누더라도 트랜스포머가 글을 이해할 수 있는지 확인하는 태스크다.
구체적으로 IMDb reviews 데이터셋의 문장을
알파벳 단위로 임베딩한 것을 input으로,
output은 binary(good/bad)값으로 하는 이진 분류 문제를 푼다.
알파벳 단위로 나누게 되면 길이가 최대 4,000까지 길어진다.
BYTE-LEVEL DOCUMENT RETRIEVAL
두 문서가 얼마나 유사한지 모델링하는 문제로,
문서를 byte/character-level로 임베딩하여 긴 시퀀스를 만들고,
압축된 representation간의 similarity를 비교하여 매칭하는 테스크다.
데이터는 input에 두 개의 논문이 들어가고, output은 두 논문간 인용이 되어있다면 1, 관련이 없다면 0으로 이진 분류 문제다.
문서의 길이는 4,000이고 두 개를 합치기 때문에 8,000까지 늘어나게 된다.
IMAGE CLASSIFICATION ON SEQUENCES OF PIXELS
2차원의 이미지를 1차원으로 만들어 입력하는 문제다.
이미지가 1차원의 긴 픽셀로 만들어졌을 때, 픽셀간 spatial relation을 트랜스포머가 학습할 수 있는지 여부를 확인한다.
데이터셋은 CIFAR-10을 이용하며 gray-scale로 변환하여 사용하는 이미지 분류 문제이다.
PATHFINDER (LONG-RANGE SPATIAL DEPENDENCY)
2차원의 공간에서 두 점이 선으로 연결되어있는지 여부를 판단하는 문제다.
위 그림에서 보듯이, 두 점이 연결되면 1, 연결되지 않으면 0으로 분류한다.
완전히 채워진 선이 아니라 점선으로 구성하여 노이즈가 들어있다.
이 태스크도 4번과 마찬가지로 2차원 이미지를 1차원으로 바꾸어 풀며,
길이는 $32 \times 32 = 1024$이다.
PATHFINDER-X (LONG-RANGE SPATIAL DEPENDENCIES WITH EXTREME LENGTHS)
위 5번 문제와 동일한데 차원을 훨씬 크게 늘렸다.
길이는 $128 \times 128 = 16384$이다.
이 문제는 5번 문제는 해결한 것과 연관지어 살펴보기 적절하다.
한 알고리즘이 같은 문제를 풀지만 짧은 길이는 풀고, 긴 길이는 못 푼다면
길이가 미치는 영향에 대해서 생각해볼 수 있다.
Baseline
Performance Baseline
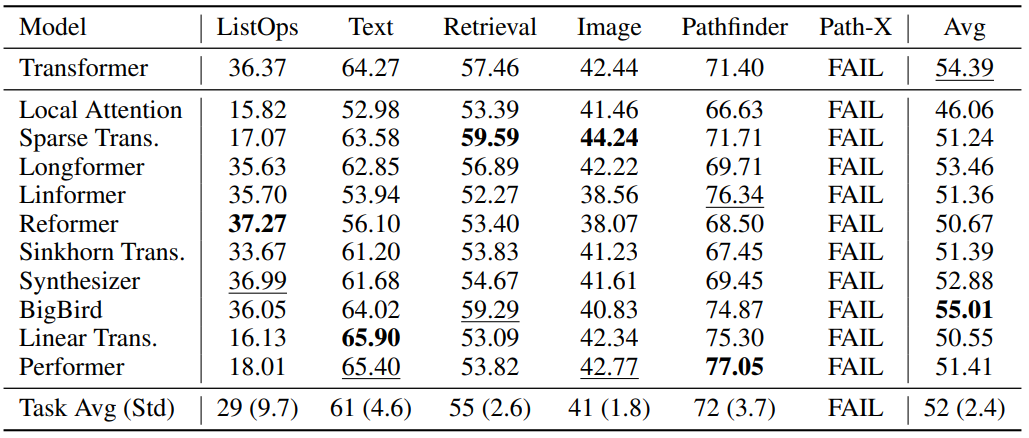
6가지 태스크에 대하여 기본 트랜스포머와 variants 10개로 실험했고,
다만 각 모델의 저자가 직접 실험한 것이 아니기 때문에 대략적인 결과라는 것을 강조했다.
6가지 태스크 모두 분류 문제이기 때문에 metric은 accuracy이며,
각 태스크에 대해 가장 높은 값은 볼드체로, 두 번째로 높은 값은 밑줄로 표시했다.
6번 문제인 Pathfinder-X에 대해선 모든 트랜스포머가 아직 풀지 못했다.
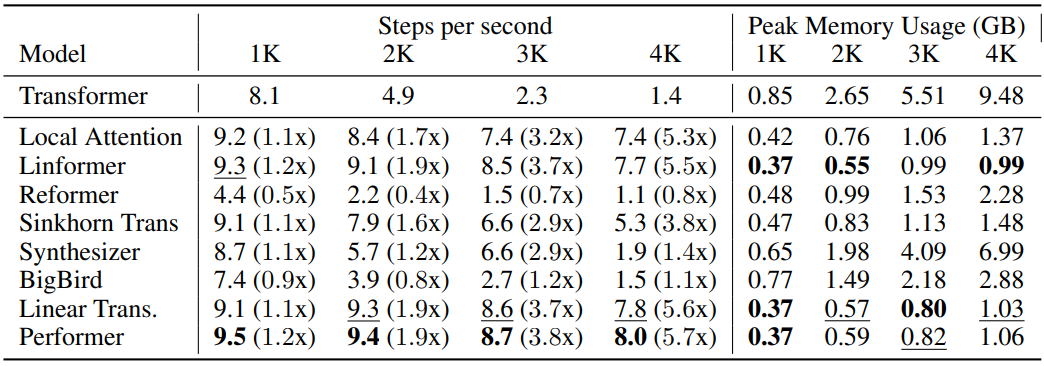
Cost Baseline
학습 속도와 메모리도 비교해보았다.
Reference
Yi Tay, Mostafa Dehghani, Samira Abnar, Yikang Shen, Dara Bahri, Philip Pham, Jinfeng Rao, Liu Yang, Sebastian Ruder, Donald Metzler
Long Range Arena: A Benchmark for Efficient Transformers https://arxiv.org/abs/2011.04006
같은 아키텍쳐를 가진 Student model $g_{\theta_s}$과 Teacher model $g_{\theta_t}$을 준비한다.
Student model은 gradient descent를 통해 업데이트하고,
Teacher model은 Student model의 exponential moving average(ema)를 통해 업데이트한다.
주어진 이미지 $\mathrm{x}$에 대하여 두 augmentation view의 쌍 $(\mathrm{x}_1, \mathrm{x}_2)$를 만들고,
각각 다른 모델에 입력해준다.
예를 들면, $\mathrm{x}_1$은 Student model에 $\mathrm{x}_2$는 Teachre model에 입력해준다.
두 모델은 마지막으로 softmax layer를 통과한다.
Teacher model의 output은 gradient가 흐르지 않게(sg; stop-gradient)
고정된 텐서로 만들고, Student model의 output과 cross-entropy를 만들어 gradient descent해준다.
예를 들면, $\mathrm{x}_1$이 입력된 Student model의 output을 $\mathrm{p}_1$이라 하고,
$\mathrm{x}_2$가 입력된 Teacher model의 output을 $\mathrm{p}_2$라고 한다면,
loss는 $-\mathrm{p}_2 \log \mathrm{p}_1$이다.
즉, DINO는 Teacher model의 output을 마치 ground truth처럼 생각하고,
Student model의 output과 cross-entropy를 구해 학습한다.
Teacher model에서 Student model로 정보를 추출(distill)하는 방식의
Self-supervised learning(SSL)이다.
프레임워크의 이름 DINO는 Self-distillation with no labels에서 따온 것이다.
안정적인 학습을 위해 centering과 sharpening이라는 테크닉을 추가했고,
다른 SSL 방식에 비해 직관적이고,
batch size가 커야 학습 효과가 좋은 contrastive learning 방식보다 효율적이다.
결과
Feature extractor를 담당하는 아키텍쳐는 ResNet50, DeiT, ViT를 이용했고,
여러 SSL 방법과 ImageNet에서 비교 실험했다.
평가 방법은 Linear evaluation(feature extractor 부분을 고정하고 output layer만 새로 학습하여 평가하는 방식)과
$k$-NN(representation을 가지고 $k$-NN으로 분류하는 방식)을 이용했다.
Linear and k-NN classification on ImageNet
위 표에서 보듯 DINO는 뛰어난 representation learning 능력을 보여주었다.
특히 $k$-NN은 fine-tuning 없이 측정했음에도 뛰어난 성능을 보여주었다.
또한 $k$-NN을 통해 좋은 퍼포먼스를 내기 위한 3가지 요소를 설명했는데,
MoCo 논문에서 제시한 momentum encoder,
SwAV 논문에서 제시한 multi-crop,
그리고 본 논문에서 ViT를 사용할 때 작은 크기의 patch의 중요성을 제시했다.
DINO는 이 3가지 요소를 모두 반영하여 학습했다.
Self-attention map from Self-supervised learning with DINO
이 논문에서 또 하나 강조한 것는 ViT를 SSL 했을 때 마지막 block의 self-attention map이 위 그림처럼
semantic segmentation에 대한 explicit한 정보를 담고 있다는 것이다.
이것이 의미가 큰 이유는 supervision으로 학습한 ViT의 attention map에서도 explicit하게 나타나지 않던 특징이, SSL을 통해 배웠다는 것이다.
Self-attention의 각 head를 하나의 색깔(클래스)로 나타내면
위 그림과 같이 실제 segmentation 처럼 visualize 할 수 있다.
Pseudocode
DINO PyTorch pseudocode
loss 부분을 보면 $\mathrm{x}_1$과 $\mathrm{x}_2$를 Teacher model과 Student model에 교차입력해서
두 augmentation 순서쌍에 대해서 모두 학습해주는 것을 알 수 있다.
Student model을 SGD로, Teacher model을 ema로 업데이트 한다.
ema의 momentum rate $l$은 cosine scheduling을 이용한다.
학습 과정에서 collapse를 피하기 위해 Centering과 Sharpening을 사용하는데, 위 코드에는 C와 tps/tpt로 나타나있다.
Centering은 output의 한 dimension이 dominate하는 것을 막지만,
모든 output이 uniform하게 만드는 성질이 있고,
Sharpening은 정반대의 성질이 있어, 두 가지를 함께 사용하여 균형을 맞춘다.
이 방법은 batch에 대한 의존성을 낮추어 collapse를 피하는 것이다.
Centering은 first-order batch statistics에 의존하고,
Teacher model에 bias term을 더하는 것처럼 $g_t(x) \leftarrow g_t(x) + c$ 해석될 수 있다.
$c$는 다음과 같은 수식의 ema로 업데이트 되며 배치사이즈에 영향을 받을 수 있다.
$ c \leftarrow mc + (1-m)\frac{1}{B} \sum_{i=1}^B g_{\theta_s}(x_i) $
$m$은 hyperparameter다.
Sharpening은 작은 값의 temperature parameter tps/tpt를 사용하여
softmax output을 normalize 해준다.
Implementation을 살펴보면 Student model의 tps는 0.1,
Teacher model의 tpt는 0.04에서 0.07로 linear warm-up을 해주는
hyperparameter다.
Hyperparameter가 은근 많은 것 같다.
Reference
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, Armand Joulin
Emerging Properties in Self-Supervised Vision Transformers https://arxiv.org/abs/2104.14294
Framework of Beyond Self-Supervision
Result1
Result2