2D Fourier transform을 self-attention 대신 적용하며,
두 개의 1D Fourier Transform $\mathcal{F}$을 hidden dimension과
sequence dimension에 두 번 연속으로 적용하는 방식을 채택한다.
두 번 fourier transform을 수행하고, 실수부(real part; $\Re$)만 output으로 사용한다.
두 개의 fourier transform에서 모두 real part를 사용하는 것보다
두 번째 output에만 사용하는 것이 더 나은 결과를 보여준다고 한다.
두 번 모두 real part를 사용할 때 기대되는 speed up은 관찰되지 않았다.
배경
Discrete Fourier Transform(DFT)
푸리에 변환은 주어진 함수를 몇 개의 주파수로 분해하는데,
이산 푸리에 변환(DFT)는 이산적인 입력 신호로 분해하며, 공식은 다음과 같다.
$X_k = \sum_{n=0}^{N-1} x_n e^{-\frac{2 \pi i}{N} n k}, \; 0 \leq k \leq N - 1 $
$N$개의 이산적인 복소수 $x_i$들을 복소수 $X_i$들로 변환된다.
푸리에 변환이 self-attention을 대체한다고 생각했을 때,
$x_i$가 input token이며, 새로운 복소수 $X_i$가 layer의 output이다.
DFT 방법 첫 번째
DFT를 계산하는 첫 번째 방법은 Fast Fourier Transform(FFT)으로,
대표적인 FFT는 Cooley-Tukey algorithm이 있다.
이 알고리즘은 Sequence length $N$을 $N = N_1 N_2$로 표현하여
계산량을 $O(N \log N)$으로 줄인다.
DFT 방법 두 번째
DFT를 계산하는 다른 방법은 단순히 DFT matrix를 input sequence에 곱하는 것이다.
DFT matrix는 Vandermonde matrix로 normalize되어 다음과 같이 구성된다.
$W_{nk} = ( \frac{e^{-\frac{2 \pi i}{N} n k}}{\sqrt{N}})_{nk}$
연산량은 더 많지만 TPU의 효과적인 matrix multiplication으로 인해 상대적으로 짧은 길이의 sequence에서는 속도가 더 빠르다고 한다.
결과
트랜스포머를 최적화하기 위한 다른 기법(Adafactor, inverse square root learning schedule, and pre-layer normalization)을 사용하지 않고,
Vanilla Transformer와 비교하기 위해 vanilla FNet만을 실험하였다.
비교를 위해 BERT-Base transformer, Linear encoder, Random encoder, Feed Forward only(FF-only) 모델을 사용했다.
Linear encoder는 2개의 learnable한 linear layer로 self-attention을 대체하며 각각 hidden dimension과 sequence dimension에 적용된다.
Random encoder는 2개의 random한 값을 가진 matrix로 self-attention을 대체하며 각각 hidden dimension과 sequence dimension에 적용된다.
FF-only는 self-attention layer를 아예 제외하고 feed forward layer로만 학습한다.
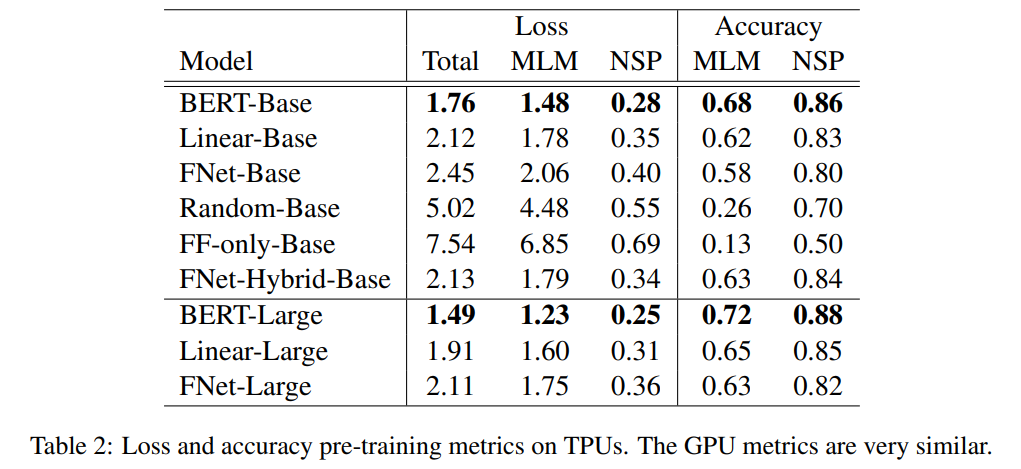
Table 2를 보면 정확도는 BERT가 Base와 Large 모델 모두 가장 높다.
FF-only Base 모델의 NSP의 정확도가 0.5인데 binary task이기 때문에 학습이 되지 않았다고 볼 수 있다.
이는 token mixing의 필요성을 나타내는 결과다.
Token mixing을 하는 Linear-Base, Random-Base를 FNet-Base와 비교해보자.
먼저 Random-Base도 token mixing이 되긴 된다. 하지만 정확도가 월등히 낮다.
그런데 Linear는 Base와 Large model에서 둘 다 FNet보다 정확도가 높다.
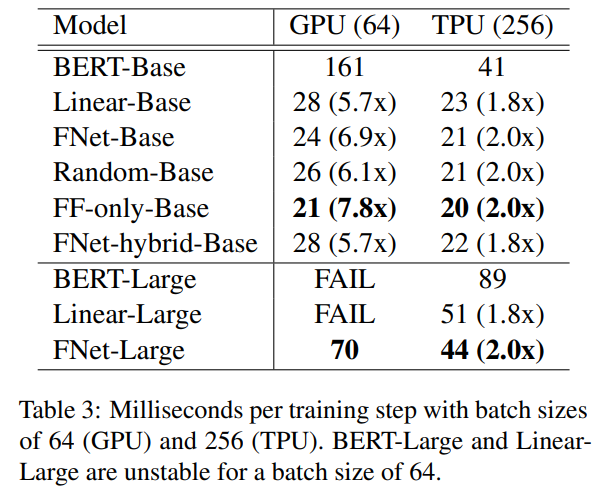
Table3을 보면 FNet이 Linear 모델보다 나은 점은 속도와 학습의 안정성에 있다는 것을 알 수 있다.
Token mixing을 하는 모델 중 FNet이 GPU와 TPU에서 둘 다 가장 빠르고,
Batch size를 64로 줄였을 때도, 학습이 실패한 BERT나 Linear와는 달리 안정적으로 되는 것을 볼 수 있다. Fourier transform을 사용했기 때문에 학습할 파라미터가 없어 속도와 안정성을 획득한다고 해석할 수 있다.
또한 task independent하고 token independent한 방식임에도 적당한 token-mixing을 통해 정확도를 어느정도 끌어올릴 수 있다는 이점이 있다.

FNet encoder architecture
Fourier transform layer