[논문리뷰] Beyond Self-Supervision: A Simple Yet Effective Network Distillation Alternative to Improve Backbones
2021년 06월 25일

프레임워크
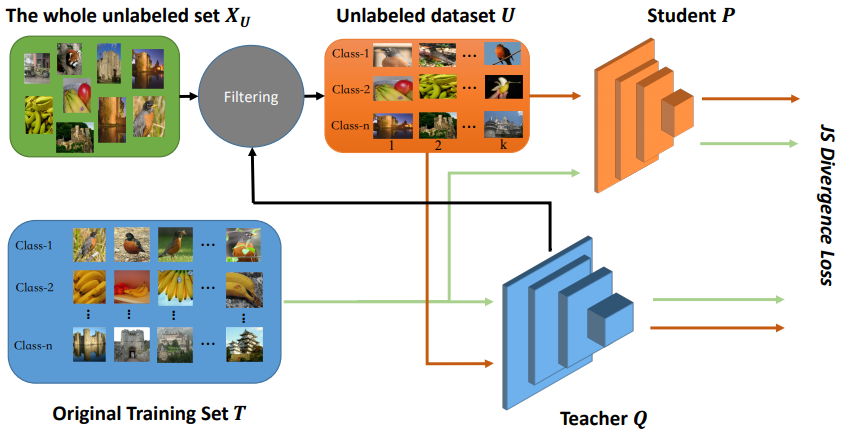 Framework of Beyond Self-Supervision
Framework of Beyond Self-Supervision
방법
- 최근 pretrained model을 이용하여 높은 퍼포먼스를 보여주는 연구가 많은데
이 논문은 pretraining의 높은 비용(낮은 효율성)을 지적한다.
- 가령 Vision Transformer가 ImageNet 22K에서 pretrain한 뒤,
ImageNet 1K로 downstream하는 방식의 finetuning을 하는데,
이는 pretraining 과정에 이미지 22K장의 방대한 양을 학습해야하기 때문에 상당한 비용이 요구된다.
- 논문은 22K장의 이미지를 이용하지 않고도 22K장을 이용한 만큼 혹은 그 이상의 퍼포먼스를 보여줄 수 있는 방법을 제시한다.
- 아이디어는 간단하다.
ImageNet 1K에 supervised set up으로 pretrain된 teacher model을 이용해
unlabeled set에서 각 category별로 score가 높은 top k개를 골라내어
추가적인 학습에 사용하고, 나머지 데이터는 사용하지 않는다.
- 공정한 비교를 위해 teacher 모델이 데이터를 선별하는 과정 전에
SIFT[2]라는 기법을 이용해 validation set과 비슷한 이미지를 미리 제외해준다.
- 예를 들면, ImageNet 22K에서 SIFT를 이용해 ImageNet 1K의 validation set과 비슷한 이미지를 제외하고,
ImageNet 1K에서 pretrain된 ResNet50을 teacher model로 사용하여,
앞서 제외하고 남은 이미지 중 각 클래스별 score가 높은 4000개를 선별하여 4M개만 사용한다.
결과
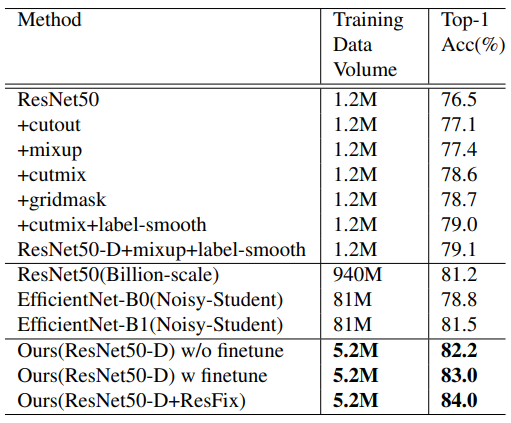 Result1
Result1
- 전체 데이터를 활용하여 학습하는 것보다
일부 데이터로 한번 학습을 끝내고,
남은 데이터를 선별해 추가적인 학습을 하는 것이
더 정확도가 높은 것을 알 수 있다.
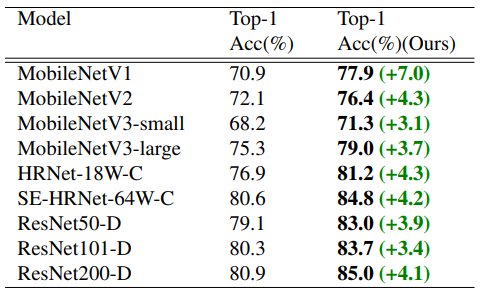 Result2
Result2
- 다른 아키텍쳐를 사용했을 때도 같은 결과를 얻는다.
개인적인 생각
- 스크래치부터 학습할 것 없이,
현재 널려있는 pretrained 모델부터 출발한다는 아이디어는 훌륭하다.
- 그러나 한번 학습을 끝낸 모델을 기준으로 데이터를 선별하는 것이
치팅인지 아닌지 여부가 관건이다.
- 공정한 과정을 거쳤다고는 하나
결국 테스트셋과 닮은 데이터를 뽑아내는 것인데
어디까지가 공정하다고 할지 애매하다.
Reference
- Cheng Cui, Ruoyu Guo, Yuning Du, Dongliang He, Fu Li, Zewu Wu, Qiwen Liu, Shilei Wen, Jizhou Huang, Xiaoguang Hu, Dianhai Yu, Errui Ding, Yanjun Ma
Beyond Self-Supervision: A Simple Yet Effective Network Distillation
https://arxiv.org/abs/2103.05959
- David G Lowe. Object recognition from local scale-invariant features. In Proceedings of the seventh IEEE international conference on computer vision, volume 2, pages 1150–1157. Ieee, 1999.